In this post, I want to address scalable system design and how to grow a system while it’s user base grows. Because talking only about the theory can become boring very quickly, I want to discuss this topic on a practical example.
Before I start with the design itself, keep in mind that there is never “the” solution. A solution that works for scenario A is not necessarily a good solution for scenario B. There are so many variables that affect a system design which can change the approaches dramatically. Further, I will address some assumptions that will define a base of the system I design. Changing one of these assumptions can lead to a poor resulting design.
While designing systems, people are usually in a very early stage of a product. There are different requirements and constraints which are not necessarily in the hand of the designers. Saying that, it is very important to discuss and challenge requirements, constraints, forecasts and assumptions. The results of these discussions is than the base of the system design.
As mentioned above, I would like to explain a theoretical topic using an example. This example should be our “journey” from a simple application to a scaled system. Let’s start 😊
Contact Tracing System
As almost every country on the world, Germany is also massively affected by the COVID-19 pandemic. As a result, german bars, restaurants, cafes, etc. are required to store guest data for at least 2 weeks in order to trace back a positive COVID-19 case and have a chance to break the infection chain.
The system addressed here should be a contact tracing application that ideally can serve for a whole city, federal state or whole Germany (not really realistic, but we want to scale 😊). Whenever someone or a group of guests visits a cafe, they should simply open an (web) app, type in and submit their contact data. If some of the cafes guests is later tested positive for COVID-19, the owners should be able to generate guest lists of that day and hour. The data should be stored for a given time (usually 14 days) and should be deleted afterwards (due to privacy restrictions).
Key components
Let’s list some of the key components from what we know about the app:
- input form, that posts small data to a server
- guest lists for a given time range
- delete mechanism after certain amount of time
- multi customers: distinguishing between the cafe to whom the data belongs to
Assumptions
When thinking about the use case, the whole system seems to be more write heavy than read heavy. In fact, there is no recurring read operations. Data is read only when the authorities asks for which can randomly be the case. Even when we have a system that generates daily reports (which is not so easy due to european/german law), we will definitely have more writes since – depending on its size – the cafe may have a lot of guests coming and going. Further, a delete mechanism – which is also required by law – will run periodically (daily) in order to fullfill the 14-day requirement and denotes also a write operation.
The guest list should only be generated when someone explicitly asks for. Further, read operations are usually limited to a given day and maybe time. Therefore, the data read should be small enough for not leading to bottlenecks.
Major Components
In a simple scenario, we would just have a web server with some application code as well as a database which could be on the same machine. But we want to serve ideally for whole Germany. Thus, a single server will sooner or later be not enough. This denotes also a “Single Point of Failure” (SPOF) since we have just one server that hosts every part of our application. If this server dies, our whole service die!
So instead using a single machine, we should go back to the assumptions and take a closer look on what denotes our service. As we have declared above, we are a write heavy application. Having this in mind, we should definitely have more than one master database that handles write operations.
Due to our not so read heavy nature, it could be ok to have less slave’s than master’s. This would also be ok considering the fact that data is very small and deleted after a while.
Further, since we distinguish between read and write, and also want to balance write operations to all master’s, we must extend our application code such that it can determine a read or a write and route it to the corresponding server.
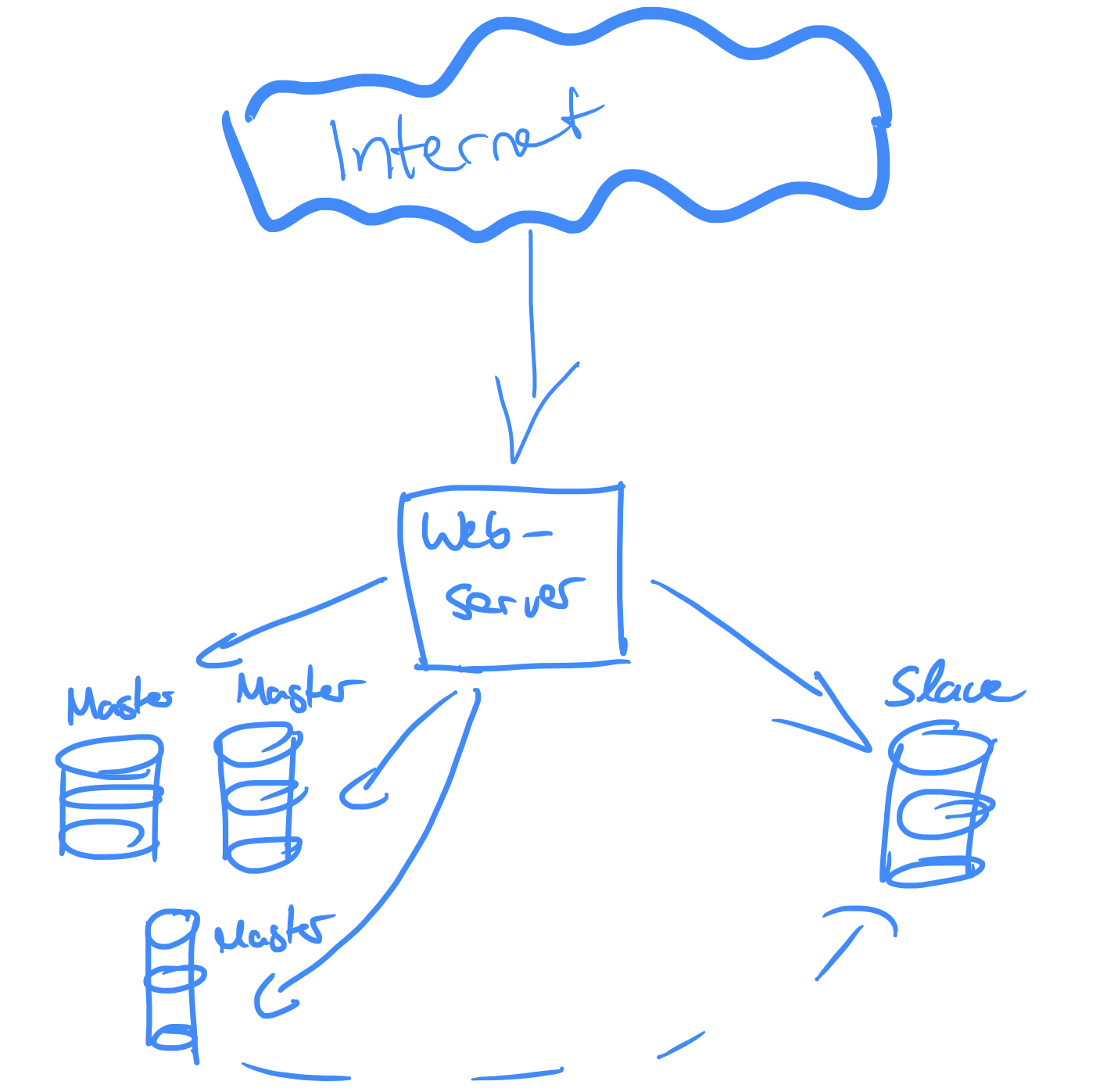
This is a good point to stop and think about the architecture. Let’s start from the beginning: The incoming requests are directly routed to the web server. The web server determines the operation (read or write) and routes the request to slave or master. The master replicates it’s state to the slave (or slaves) which is requested by the web server for read requests.
This architecture has an SPOF: the web server which handles every request itself. But what if it dies? What if our application gets popular and can not grow vertically anymore?
It seems to be reasonable to introduce something in front of the web server that is responsible for routing the requests. Doing this, we solve our load problem as well as we can set up new web servers when our application gets popular. The load balancer decides which web server should handle the request (more on that later).
In fact we do not solve the SPOF here since we delegate the routing from the web server to the load balancer. But however, the load balancer is only responsible for the routing and thus more robust. Further, we can simply add multiple load balancers in order to avoid the SPOF. There are different approaches for multiple load balancers, such as active-active or active-passive. In active-active, the load balancers send a heartbeat (a small chunk of data packets) to each other. If one of the load balancers does not send a heartbeat anymore, the second load balancer take over the job and routes all data. In active-passive, we have also heartbeats where the passive load balancer acts as a backup. If the active one dies, the passive load balancer becomes the active one.
At this point, we should also think about or master nodes. Since we have a write heavy application, we need to balance somehow the write operations across the master’s. For this purpose, we can simply put another load balancer in front of the masters and let easily the load balancer decide the routing.
So our new architecture looks like:
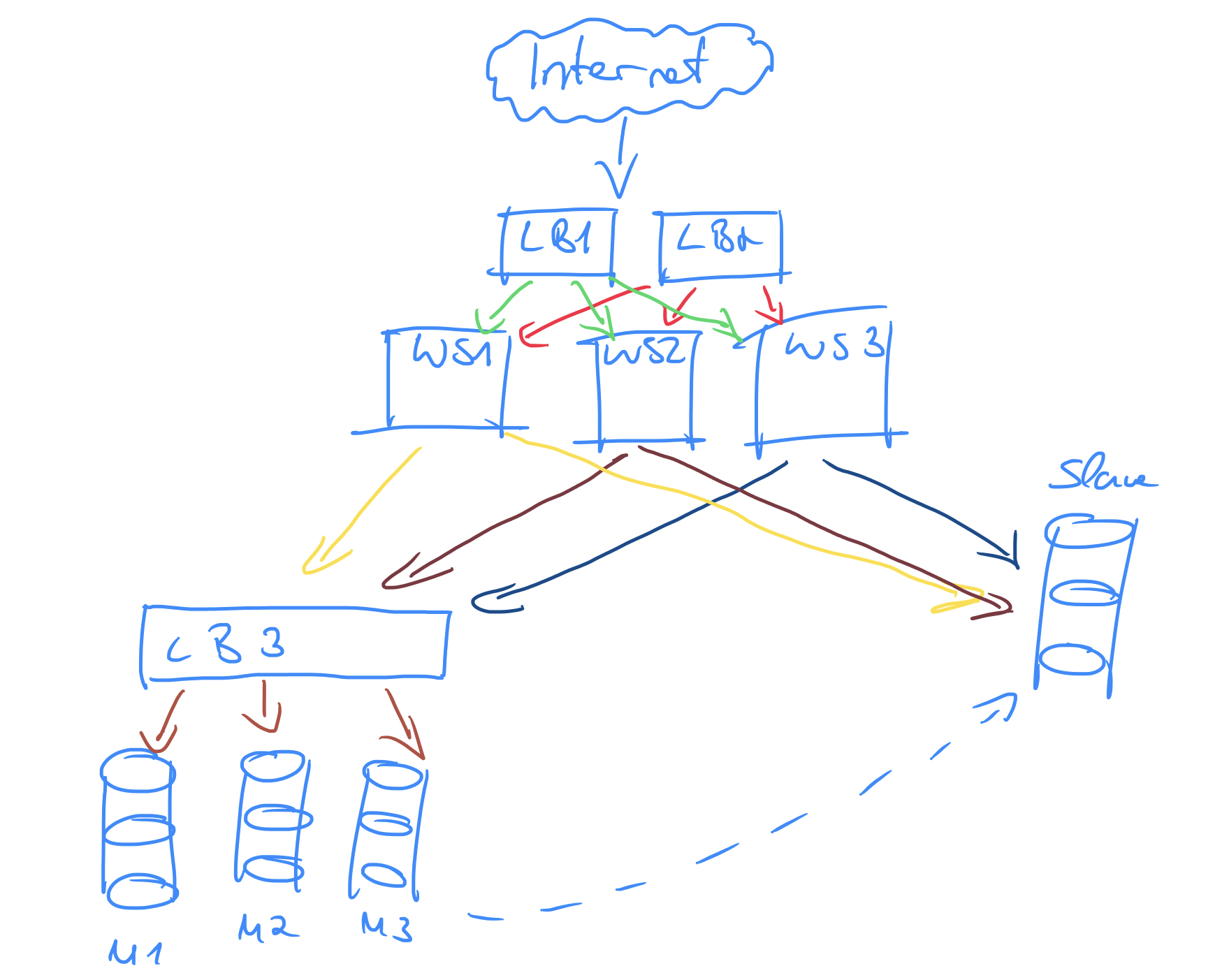
Now, we have two load balancers that route requests to one of the web servers which determines the request type (read or write) and routes the request to the slave or to load balancer 3. The 3rd load balancer forwards the request to one of the master’s. The master(s) replicated it’s data to the slave which is responsible for read requests.
But how does the load balancer determine the best server to route the request? There are different approaches to do this:
- Round Robin: The first request from a user is routed to server 1, the second to server 2, and so forth.
- Advantage: there is no need for an bi-directional communication to the servers
- Downside: no way to „control“ the mechanism. Server1 can be overloaded because every requestor comes the first time whereas server2 is idle
- Downside 2: session management is definitely broken because sessions are saved on the server. If the user is routed to another server every time, there is no consistent session. We can set up a dedicated session server or let the load balancer manage the sessions but both approaches introduce a new SPOF.
- Downside 3 (for DNS based round robin): the browser as well as the operating system will cache the IP address requested from the DNS. So if you are going to make the request to a known domain, the IP address will requested from the cache (depending on TTL) which will be the same as the first time.
- Regional/Logical Constraints: such as routing all requests from a country/in a given range to the corresponding servers
- Advantage:
- Downside: the load is usually not evenly distributed. For instance, there will be more persons starting with M than Z or your application can get popular in one country but still not in another.
- Storing the server’s id into a cookie: when the user visits the application the first time, he will randomly routed to a server. The id of the server can stored as cookie and whenever the user uses the app again, the destination server is read from the cookie.
- Advantage:
- Downside: giving internal info (such as the internal IP of the destination server) price to the user. However, this can be avoided by the load balancer when he sends an encrypted version (say a hash) of the IP to the client.
- Service Based Servers:
- Random: for instance, calculating the server by %10
for instance, the least busiest, due to regional constraints, dedicated service based servers, etc.
Scaling
At this point, we have reached a complex architecture in order to fit our requirements. Let’s discuss our current setup before we talk about further optimizations.
In general, if reasonable, we should prefer to scale vertically then horizontally wherever possible. Vertically scaling means throwing money on the problem (buying new and expensive hardware) in order to solve it. For instance, we can simply extend our disk space and/or speed I/O by using SSD’s. We can use RAIDs to speed up (RAID0) or mirror data (RAID1) or do both (RAID10).
If we came to the boundaries of possibilities, we can think about vertically scaling (what we did above). But still: even if we horizontally scale, we should pay attention to vertical scaling. Whenever possible, our architecture should technically allow vertical scaling. Scaling vertically can be very expensive, but less complex.
Recall how we defined our key components and assumptions: the application is write heavy, but the data written will be deleted after a (short) while. However our application should be used by a lot of users. So I would suggest to find a trade-off between a vertical and horizontal scaled infrastructure.
Caching
Caching is relevant for read heavy applications that need complex queries to retrieve data. A cache is a simple key-value store that you can request before executing the complex and expensive query. If the cache holds the data we can simply return it. If not, we bite the sour apple, execute the query and store the result into a cache (together with one or more invalidation criteria). Depending on the use case and infrastructure, there are multiple ways to cache:
- File Based Caching:
- Advantage: static content (html, jpeg, etc) are usually very fast delivered by web servers
- Downside: when something in the caching file get changed, all cached files have to be modified or deleted and regenerated
- RDMS Cache (for instance MySQL): a config parameter that can be set. If a query is executed, the result is cached until the data base has changed. If not, the cached data will returned every time the query is executed or a TTL is reached.
- Advantage: avoiding expensive queries
- Downside:
- RAM caching (for instance Memcached, Redis, MySQL memory storage engine): holds data in the RAM. Check first whether the data is stored in the RAM. If not, query the database and put the result into the cache in order to have it for the next time.
- Advantage: very very fast, since it is in the RAM
- Downside: cache can get too big and needs to somehow garbage collected. This can be done by a default TTL, “data is not touched since X amount of time” or simply an LRU.
- Downside 2: data is not persisted and is lost once it is not in the RAM anymore (reboot, garbage collection, power off, etc)
Recall our requirements, where we have defined sporadic reads, we do not need caching that much. Even if we could pre-generate guest lists for a given day and/or time and cache, there is no real use case for caching as we deal with a very flat data and thus, it is not expensive to query.
However, introducing caching is not a big deal. We can keep this in mind and introduce whenever necessary.
Replication
We have talked a lot about master and slave architecture. Let’s define some key points:
- Master: a database to which data is written
- Slave: an exact copy of the master
Whenever the master executes a query, the query is synced to the slave. The slave executes the query and is up to date with the master. It is important that only master gets new data as otherwise, when manipulating data on the slave, the replication will brake.
Advantages: there is at least one copy of our entire database present at failures – in an ideal world we could plug off the master and plug in a slave (to be the new master).
Downside: we introduce a new SPOF. There is only one master which writes data. If the master dies, people can browse data but can not write. We can still promote the slave to a master, but this takes a time to come up.
- Possible solution: master-master architecture. There are at least 2 masters, which can be either chosed by the load balancer or got written both and then synced with each other. If one master dies, there is still another there and no downtime.