The last few days I had a little bit more time to dive into theory. I was wondering how to effectively search single values in unsorted, large amounts of data (e.g. files larger than 1GB).
There are two key problems in such an issue: the data is unsorted, meaning that you can not search in O(log n) with binary search. The second problem is that the data is large (multiple Mega-/Gigabytes), which means that you can not load everything in the memory.
The Problem with Large Amounts of Data
Let’s imagine you have a unsorted 10 GB file of strings. You want to sort all strings by the first character of each line. How would you do this? The very first thought would be to apply sorting algorithms (quick sort, merge sort, etc.) to the whole data set. But this would require to load 10 GB in the memory, which is quite ineffective (and impossible on most systems).
Creating a file per character could be one way. Doing this splits the 10 GB file in 26 smaller files (we assume that each character has the same number of strings). Instead of sorting a 10GB file, you would sort a file with approximately 350 MB (which is much as well. But better than 10GB). You can apply this approach as long as you want. After you have sorted the single files you can merge them back to a single large file. This approach is called “external sort”.
Bitvector
Another way to handle large data – especially if you just want to search values – is using a Bitvector. Let’s assume you have an unsorted array of several hundred thousand 8 bit values. Given a value, you want to know whether it is in the array or not. How can you do this effectively? Well, using bitvectors.
Bitvectors are similar to Hashmaps, where each bucket has a bit sequence that represents the integers (or any other data type) added to the vector. Imagine a Hashmap where you add an integer as your key and a boolean true as the value, which is one byte (8 bits) in size (and indicates that the integer is in the map). Whenever setting “true” (00000001 in binary notation) to a Hashmaps key, you would set one bit and waste the remaining 7 bits! We can do that better.
Instead of using the values as the key, we use buckets that store binary representations of the integers. Adding a new integer to the bucket is realized by binary addition of the bucket’s value and the new integer. Doing this enables a comfortable way to store the information of each value without necessarily storing the value itself.
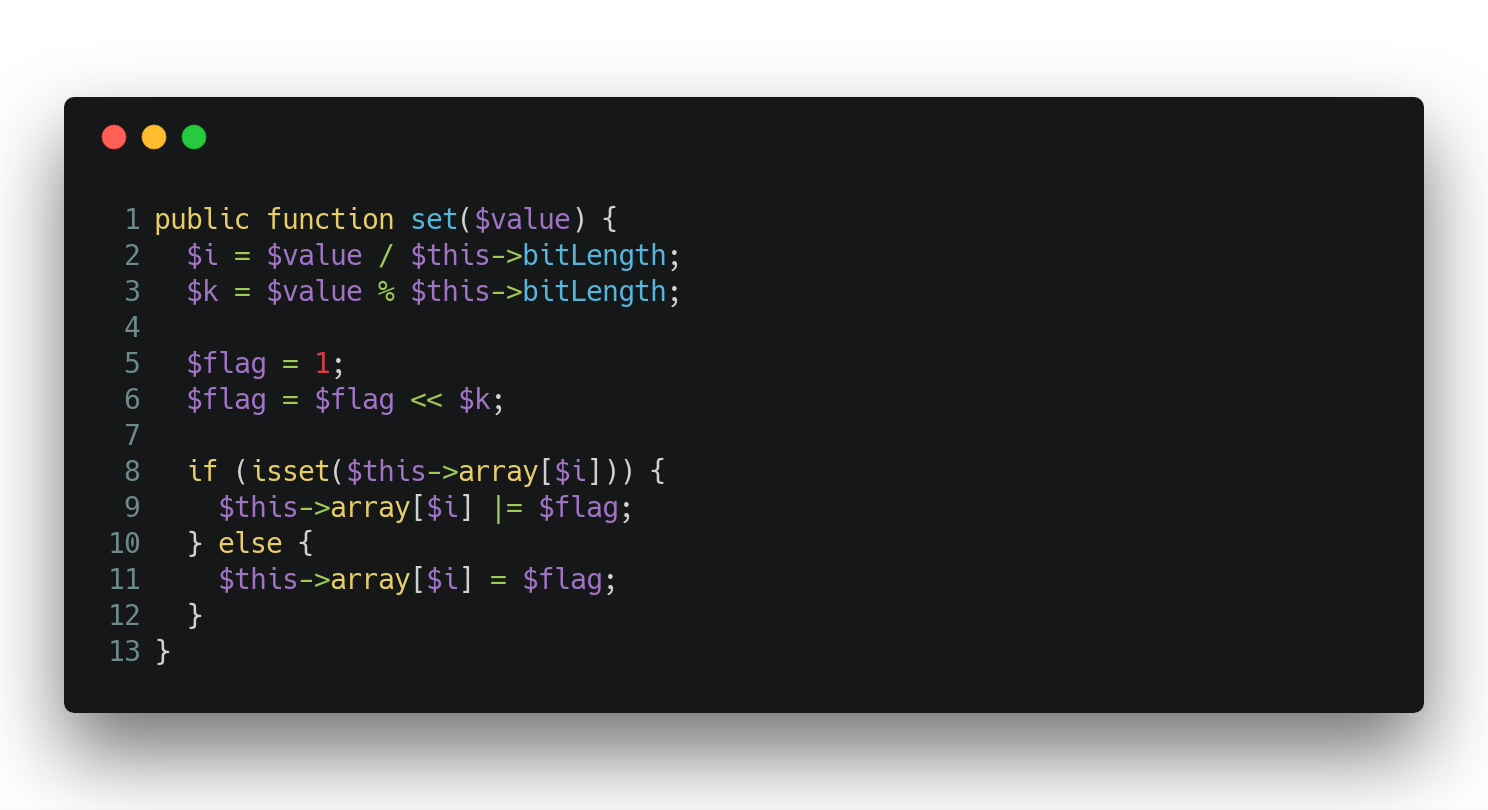
Adding values
Adding values is quite simple. Let’s assume that we have a 0 bit sequence at the beginning and want to add the value 32 to the 8 bit vector. We first need to find the appropriate bucket. Then, we need to retrieve the bit flag and apply the logical OR to the bucket’s bit sequence:
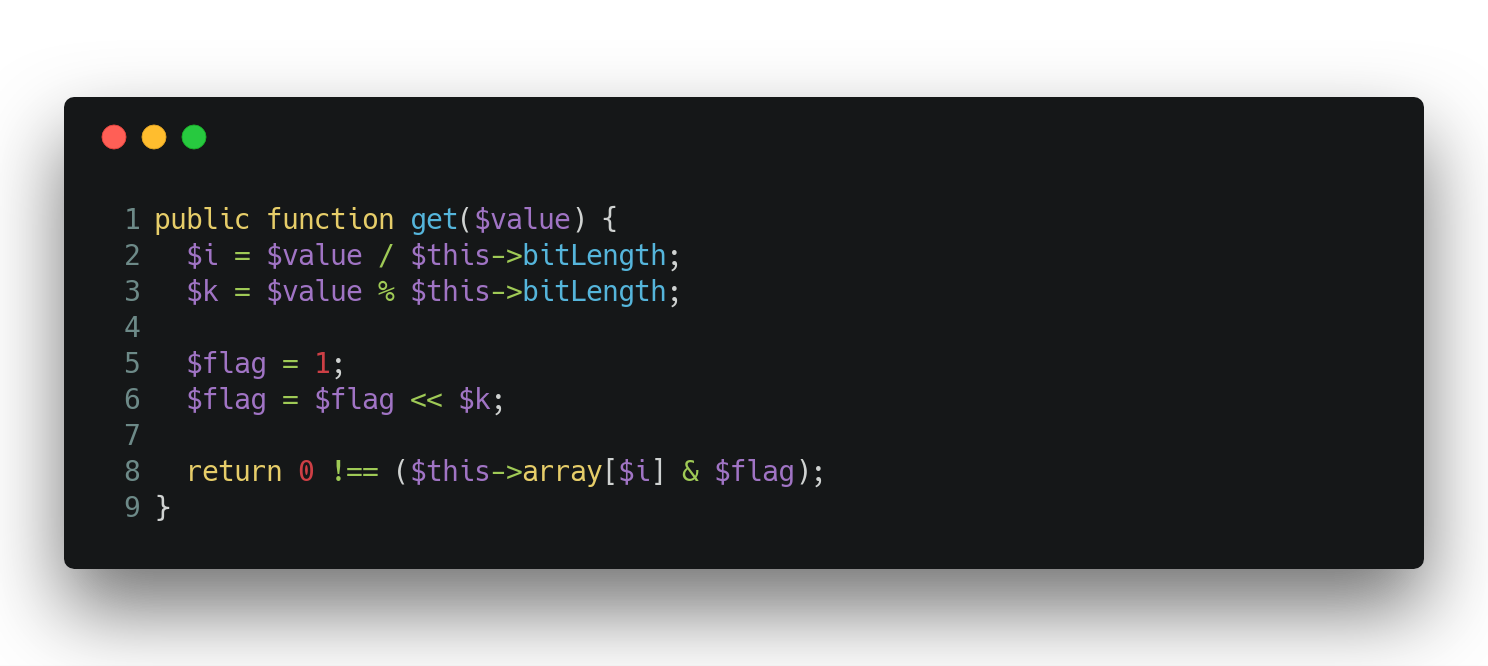
Retrieving values
In fact, there is no retrieving. You can just check if a specific value is in the vector or not. Given a value, applying the logical AND to the bit sequence returns 0 or a value greater than 0. Greater than 0 means that the value is in the vector. 0 is returned by the logical AND when the value is not in the vector:
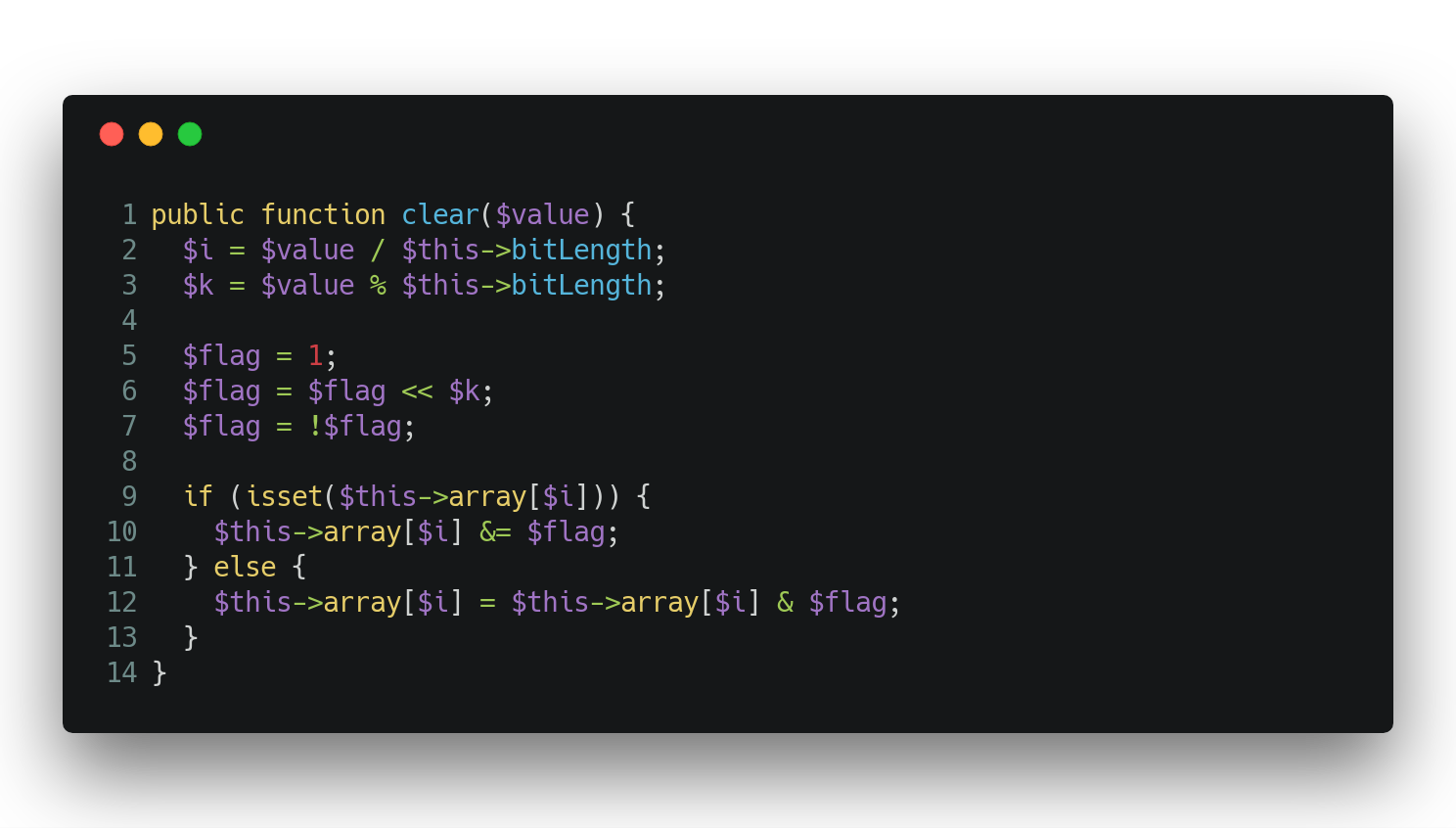
Clearing Values
Clearing uses the negated flag for applying the logical AND in order to remove the value (clear) from the array:
 Conclusion
Conclusion
There are multiple ways to solve problems regarding to large amounts of data. Splitting and handling externally is one way. Bitvectors, where you store values efficiently,is another. This two approaches are just two of many. There is no “best solution”, it depends on the situation. And maybe you can use a combination of them!
Bitvectors are going to be a part of PHPAlgorithms, my PHP library for algorithms and data structures. The goal is to have a Bitvector for each primitive data type (integers, strings, etc.). For this purpose, there is the interface IVector, that provides the methods shown above and have to be implemented. Stay tuned!
For more information, you can check the following sources:
- Algorithms: Bit Manipulation
- Array of Bits
- Wikipedia
- What are bit vectors?
- Question 7 in chapter 10 in Cracking The Coding Interview handling “missing integers”.
Source Code pictures made with ❤️ at carbon.now.sh